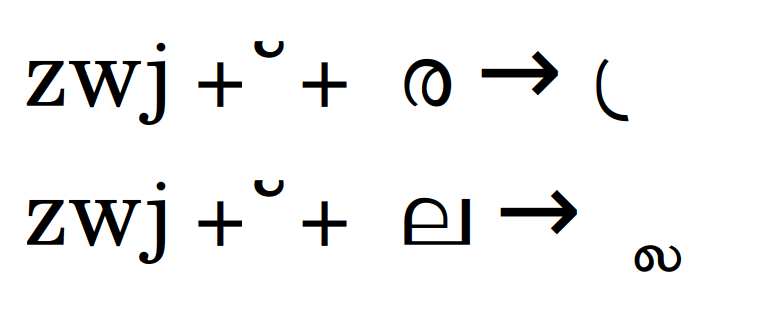‘Chingam’/ചിങ്ങം (named after the first month of Malayalam calendar) is the newest libre/open source font released by Rachana Institute of Typography in the year 2024.

It comes with a regular variant, embellished with stylistic alternates for a number of characters. The default shape of characters D, O, ഠ, ാ etc. are wider in stark contrast with the shape of other characters designed as narrow width. The font contains alternate shapes for these characters more in line with the general narrow width characteristic.
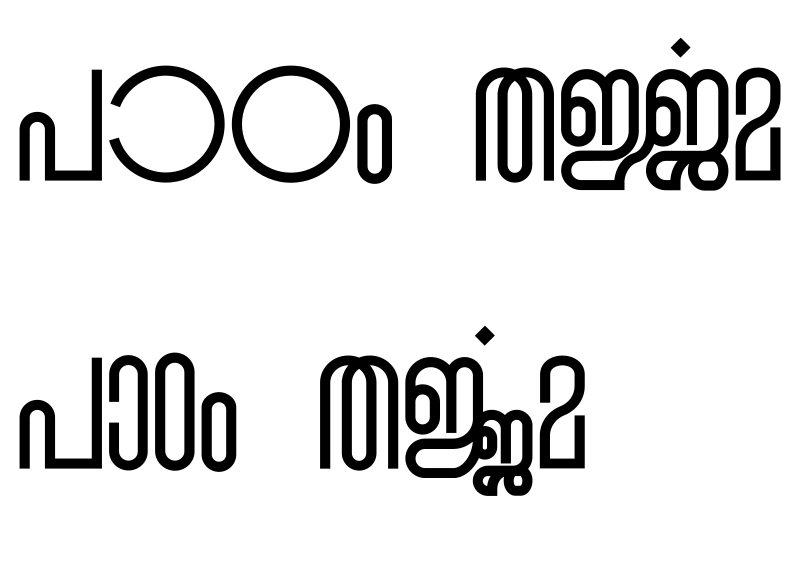
Users can enable the stylistic alternates in typesetting systems, should they wish.
- XeTeX: stylistic variant can be enabled with the
StylisticSet={1}option when defining the font viafontspecpackage. For e.g.
% in the preamble
\newfontfamily\chingam[Ligatures=TeX,Script=Malayalam,StylisticSet={1}]{Chingam}
…
\begin{document}
\chingam{മനുഷ്യരെല്ലാവരും തുല്യാവകാശങ്ങളോടും അന്തസ്സോടും സ്വാതന്ത്ര്യത്തോടുംകൂടി ജനിച്ചിട്ടുള്ളവരാണ്…}
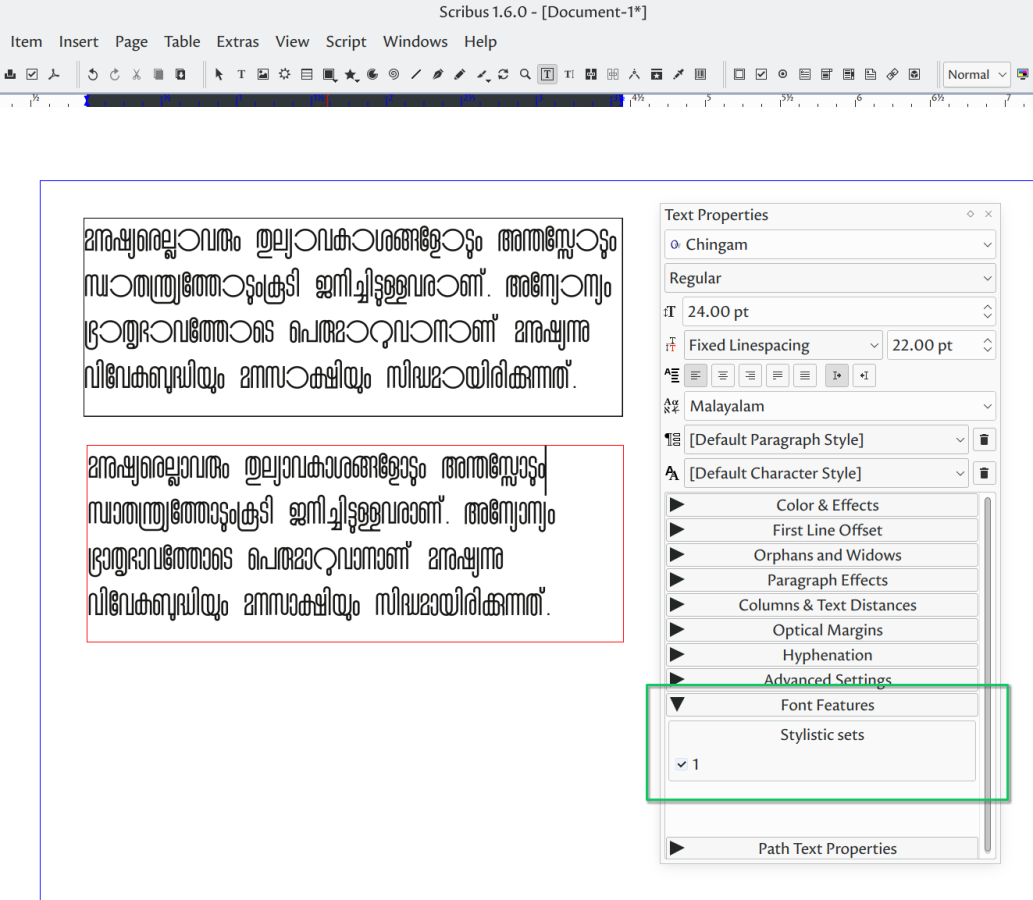
\end{document}- Scribus: extra font features are accessible since version 1.6
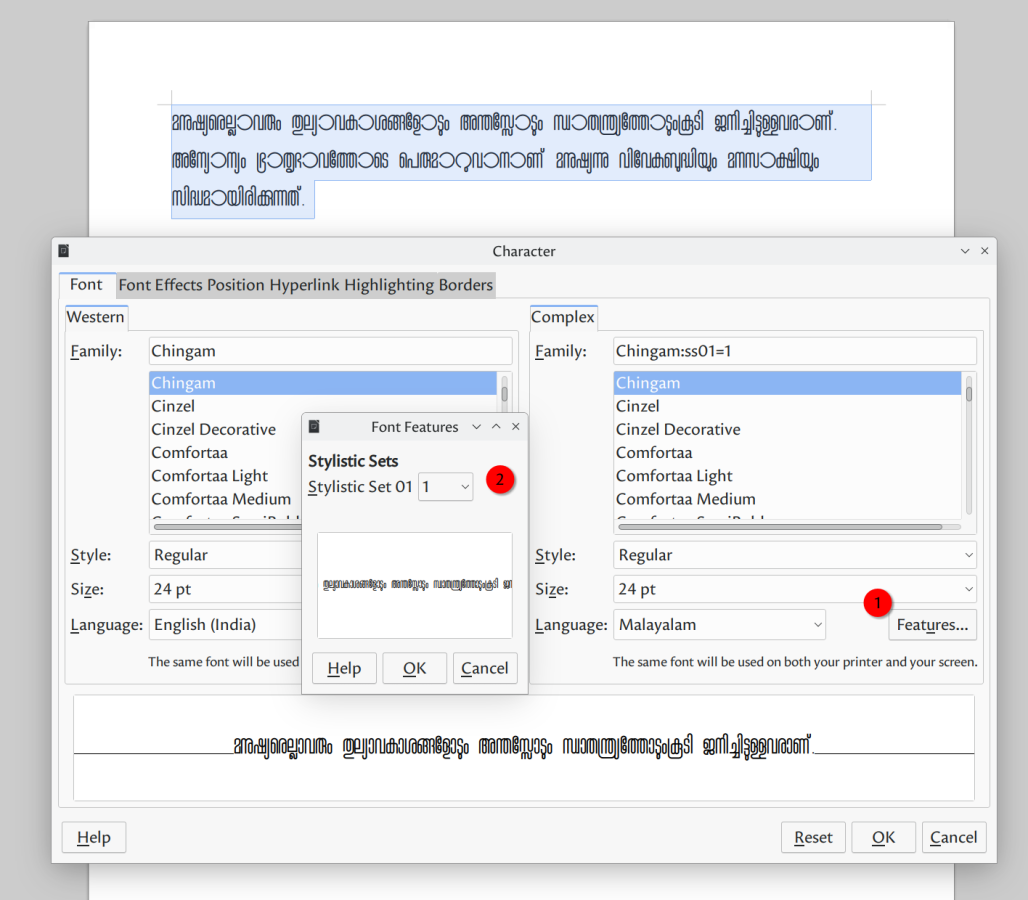
- LibreOffice: extra font features are accessible since version 7.4. Enable it using
Format→Character→Language→Features.
- InDesign: very similar to Scribus; there should be an option in the text/font properties to choose the stylistic set.
Development
Chingam is designed and drawn by Narayana Bhattathiri. Based on the initial drawings on paper, the glyph shapes are created in vector format (svg) following the glyph naming convention used in RIT projects. A new build script is developed by Rajeesh that makes it easier for designers to iterate & adjust the font metadata & metrics. Review & scrutiny done by CVR, Hussain KH and Ashok Kumar improved the font substantially.
Download
Chingam is licensed under Open Font License. The font can be downloaded from Rachana website, sources are available in GitLab page.